MySQL索引底层原理
MySQL索引底层原理探究
索引原理
这里主要讨论一下 MySQL InnoDB 存储引擎,基于B-树(但实际上MySQL采用的是B+树结构)的索引结构。
一次索引的过程大致如下图所示:
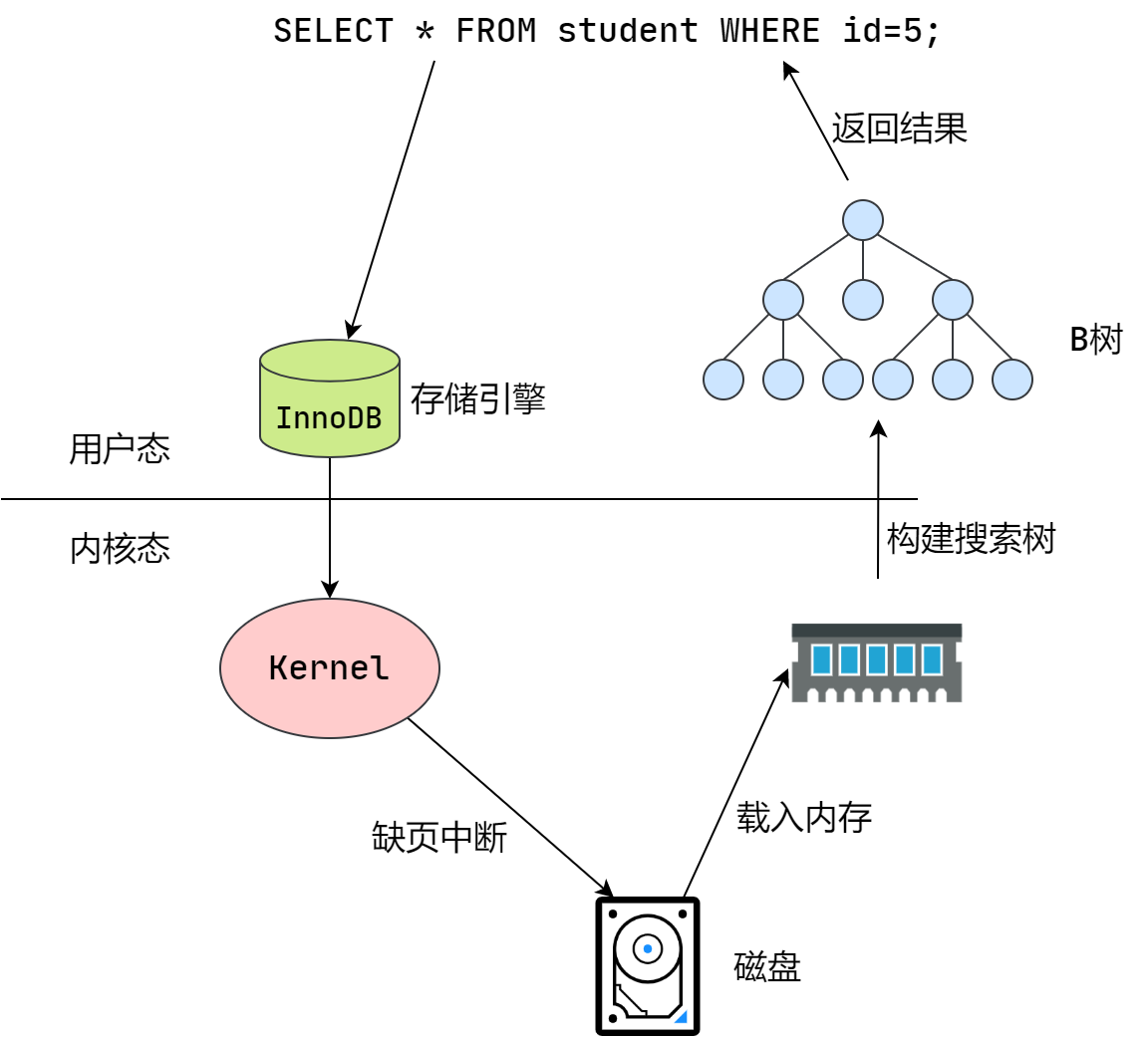
首先来看一下磁盘的结构,其示意图如下所示:
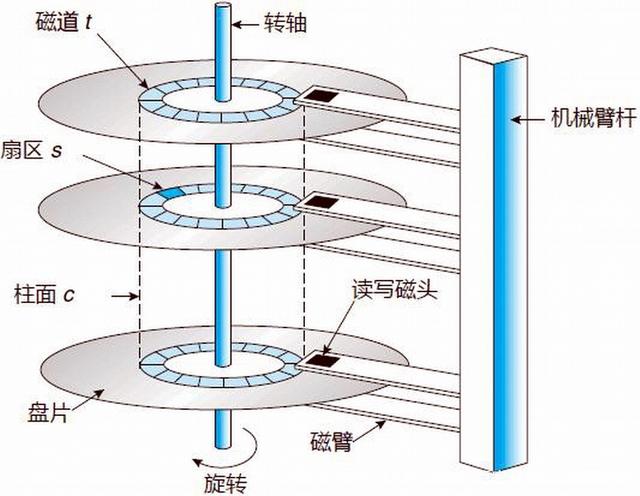
读/写磁盘某一位置的步骤如下:
- 首先根据柱面号,移动读写磁头,使磁头移动到相应的柱面上,这一过程被称为定位或查找;
- 所有磁头都定位到柱面号对应的磁道上后,这时根据盘面号来确定指定盘面号上的具体磁道;
- 盘面确定后,盘片开始旋转,将指定扇区号的磁道段移动至读写磁头下;
经过以上步骤,指定数据的存储位置就被找到了,这时就可以开始读/写操作了。
可以看到,磁盘 I/O 依靠的是机械运动,其性能所在主要分为如下三个指标:
- 寻道时间(seek): 指将读写磁头移动到指定磁道上所需要的时间,这部分时间代价最高;
- 旋转延迟时间(rotation): 指磁盘旋转将目标扇区移动到读写磁头下方所需的时间,其取决于磁盘的转速;
- 数据传输时间(transfer): 指完成数据传输所需的时间,其取决于接口的数据传输速率;
对于操作系统来说,当程序需要读取的数据不在内存中时,这时就会触发一个缺页中断,那么系统就会向磁盘发出读信号,磁盘会按照 Block 进行读取,将其载入内存,通常一个 Block 为 16K。
在操作系统的内存管理机制中,它是以 Page 为单位的,通常为 4K 或 16K,而一个 Block 的大小则是 Page 的整数倍。
假设现在从磁盘上读取了 2000 万的索引到内存上,如果使用 AVL 二叉平衡树来存储,如图所示:
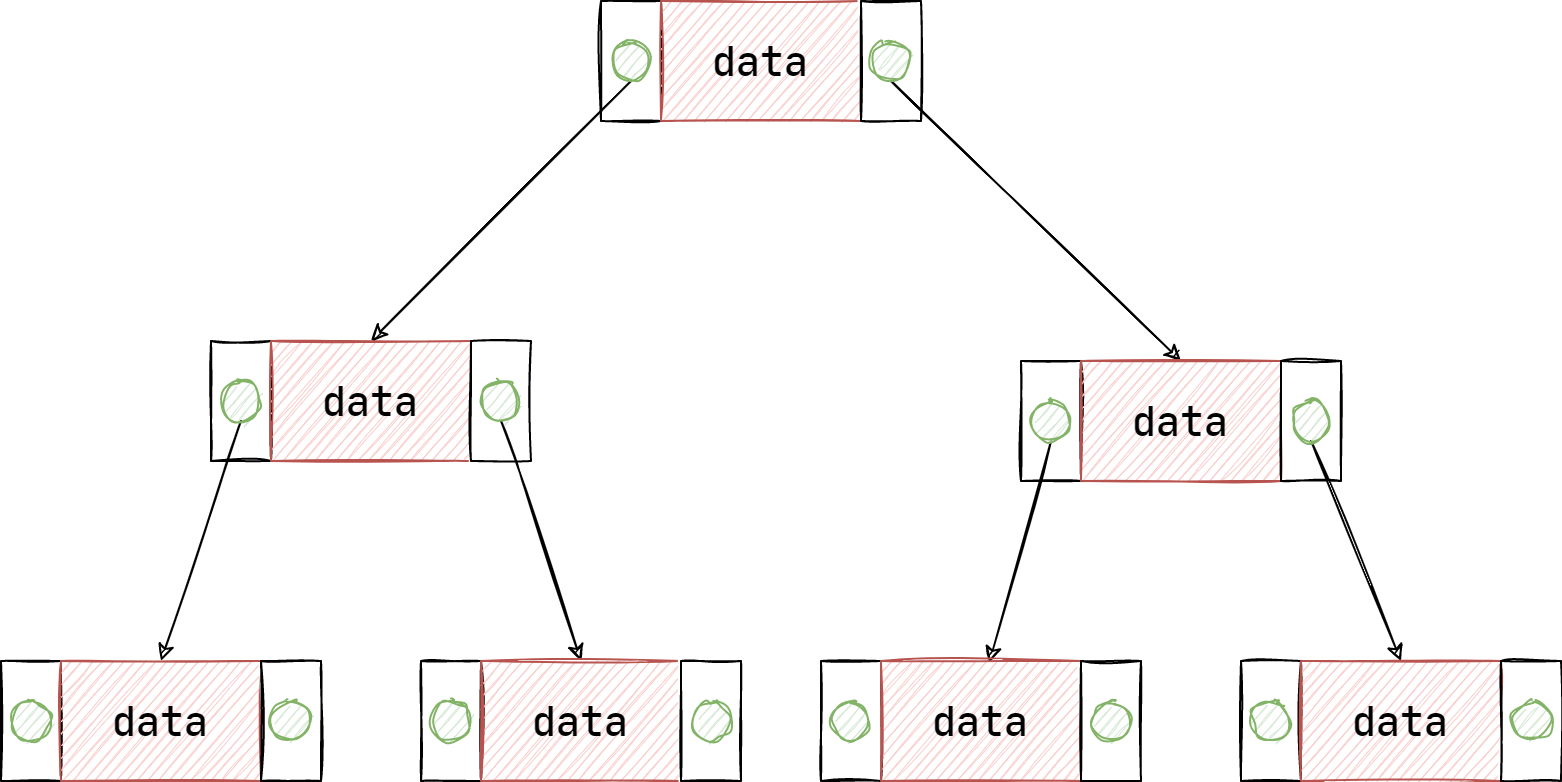
其中,每个二叉树节点只能存储一个索引,那么其树高大约为 \(log_220000000\approx25\),也就是说,如果在最坏的情况下,即每一层的节点都位于不同的 Block 中,那么总共需要 25 次磁盘 IO 操作。
而 B- 树则是一个 m 阶的平衡树,通常 m 取 300~500,即一个节点下有 m 个子节点。如果使用 B- 树的结构来进行存储,假如此时 m 取 500,那么其树高大约为 \(log_m20000000=log_{500}20000000\approx3\),也就是说,在最坏的情况下,只需要 3 次磁盘 I/O 操作即可完成。通常 m 的大小取值取决于一次磁盘 I/O 操作所读取的内容能刚好存储在一个节点中。
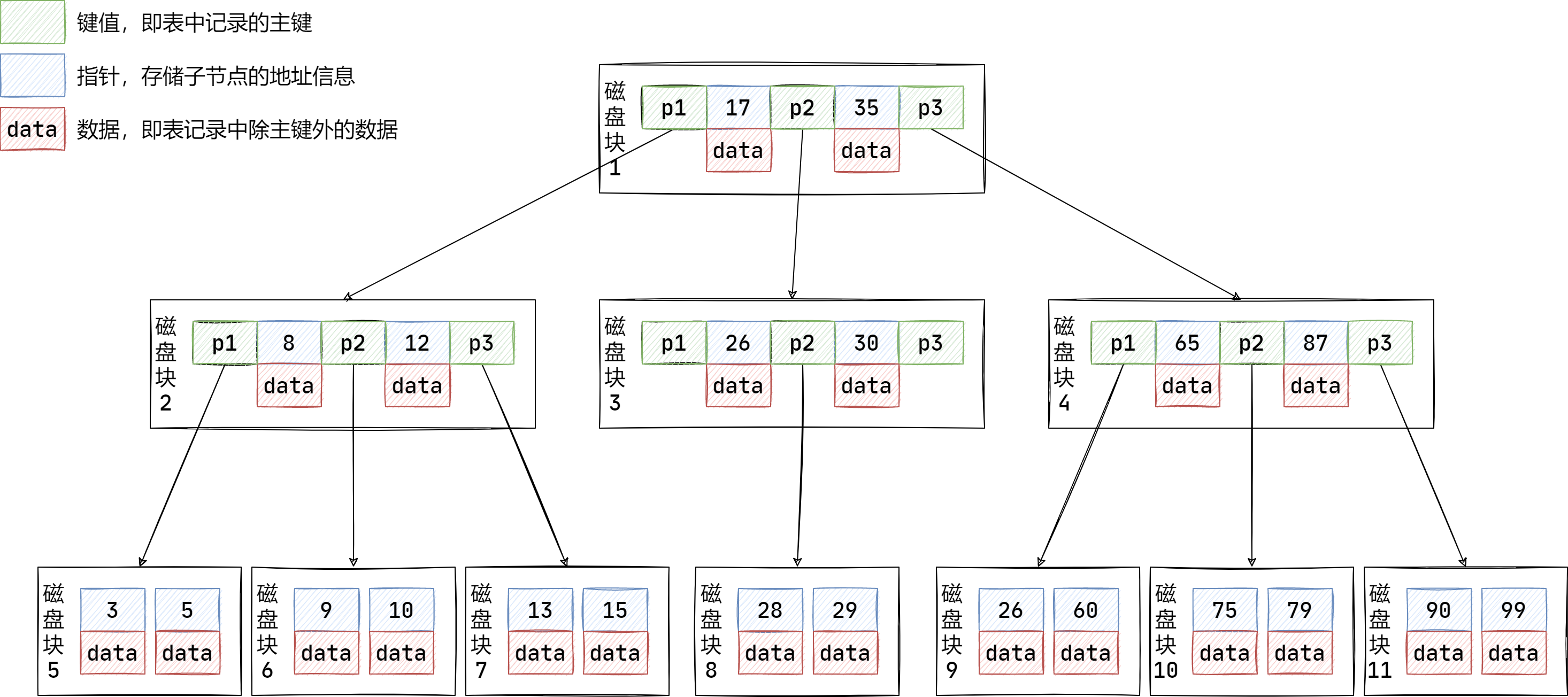
从上图可以看到B-树存在的缺点:
- 每个节点中有 Key,也有 Data,但是每一个节点的存储空间是有限的,如果 Data 数据较大时会导致每个节点能存储的 Key 的数据很小;
- 当存储的数据量很大时同样会导致B-树的高度较大,磁盘 IO 次数花费增大,效率降低;
因此针对如上缺点做出了优化,形成了B+树的数据结构,如图所示:
那么 MySQL 最终为什么要采用B+树存储索引结构呢,那么看看B-树和B+树在存储结构上有什么不同?
- B-树的每一个节点,存了关键字和对应的数据地址,而B+树的非叶子节点只存关键字,不存数据地址。因此B+树的每一个非叶子节点存储的关键字是远远多于B-树的,B+树的叶子节点存放关键字和数据,因此,从树的高度上来说,B+树的高度要小于B-树,使用的磁盘 I/O 次数少,因此查询会更快一些。
- B-树由于每个节点都存储关键字和数据,因此离根节点进的数据,查询的就快,离根节点远的数据,查询的就慢;B+树所有的数据都存在叶子节点上,因此在B+树上搜索关键字,找到对应数据的时间是比较平均的,没有快慢之分。
- 在B-树上如果做区间查找,遍历的节点是非常多的;B+树所有叶子节点被连接成了有序链表结构,因此做整表遍历和区间查找是非常容易的。
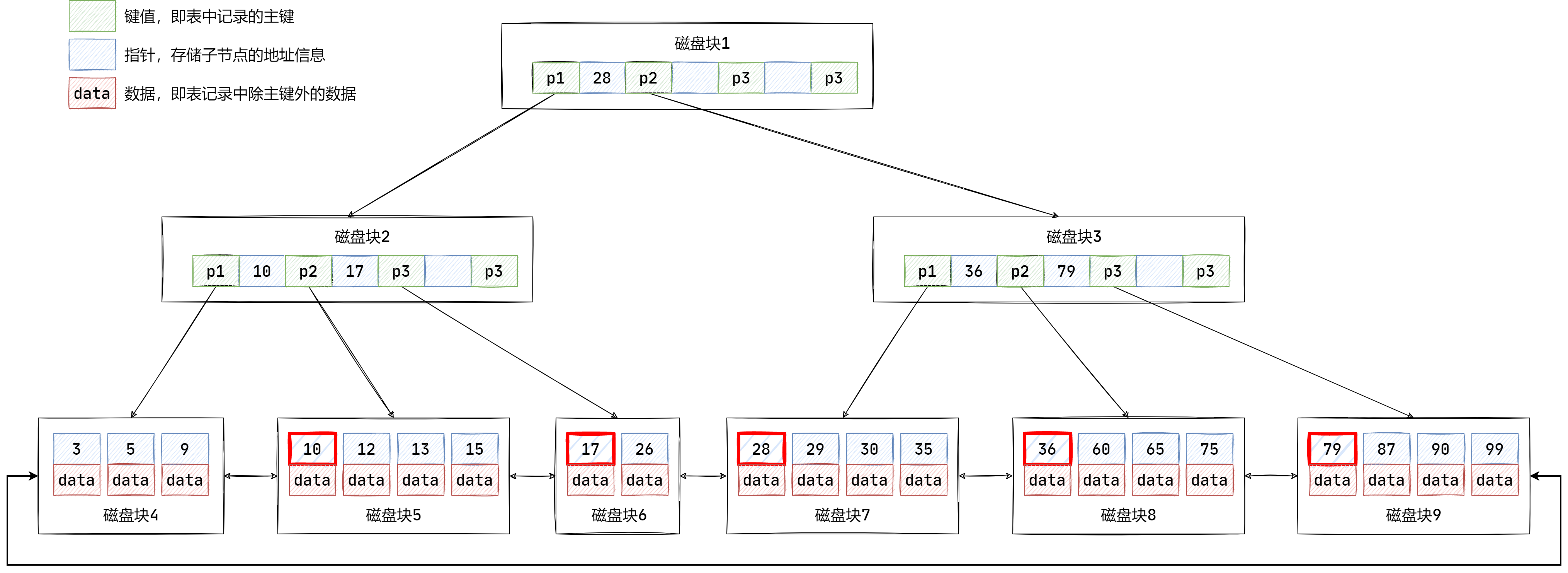
现在有这样一张数据表:
mysql> select * from student; |
其中,主键字段为 uid,那么对于不同的业务场景,其查询的方式是不同的。
情况1
查询语句如下:
SELECT * FROM student WHERE uid=5; |
使用 explain 关键字查看该语句的搜索细节如下:

观察 type
字段可知该查询为常值查询,rows
字段则表示该查询只遍历了 1 行,也就是从 B+ 树的根节点开始进行搜索:
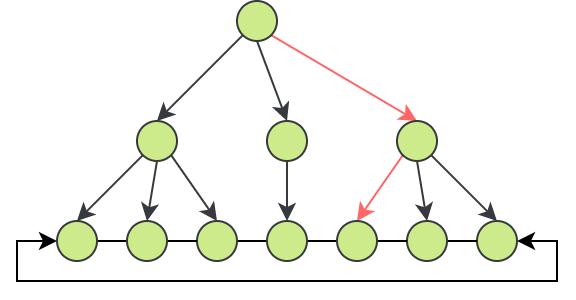
情况2
查询语句如下:
SELECT * FROM student WHERE uid<5; |
使用 explain 关键字查看该语句的搜索细节如下:

观察 type
字段可知该查询为范围查询,rows
字段则表示该查询遍历了 4 行,也就是从 B+
树的叶子节点所在层的双向链表进行查询:
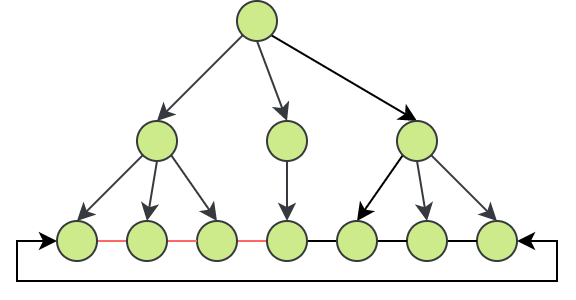
情况3
查询语句如下:
SELECT * FROM student WHERE name='linfeng'; |
使用 explain 关键字查看该语句的搜索细节如下:

观察 type
字段可知该查询为整表查询,rows
字段则表示该查询遍历了该表的所有行,这是因为所查询的 name
字段并不存在索引。也就是从 B+
树的叶子节点所在层的双向链表进行查询,且遍历整个链表。
情况4
现在使用如下语句为 name
字段添加索引,将其设置为普通索引:
create index nameidx on student(name); |
查看所有是否创建正确:
mysql> show create table student\G |
现在该表中就会存在两个索引,一个是主键默认创建的主键索引,另一个则是刚才所创建的普通索引,也称为辅助索引。那么在构建 B+ 树时,会不但会构建主键索引的 B+ 树,还会构建辅助索引的 B+ 树,且在辅助索引的 B+ 树的节点中的 data 存放的便是主键字段。
现在执行如下语句:
SELECT uid FROM student WHERE name="linfeng"; |
使用 explain 关键字查看该语句的搜索细节如下:

观察 Extra
字段可知,其查询是通过二级索引树进行查找。
情况5
现在执行如下 SQL 语句:
SELECT * FROM student WHERE name="linfeng"; |
使用 explain 关键字查看该语句的搜索细节如下:

与上述一种情况不同的是,此次查询的 Extra 字段变为了
NULL,这时因为在二级索引树上查找目标值只能得到其主键值,而现在需要主键值所在行的所有数据,那么需要执行如下过程:
- 现在二级索引树上根据普通索引查找得到主键值;
- 然后在主键索引树上根据刚才得到的主键值进行查找得到所有数据;
如上过程称之为 回表。所以,如果发生回表操作,也就会产生更多的查找和磁盘 I/O 操作,会更耗时。
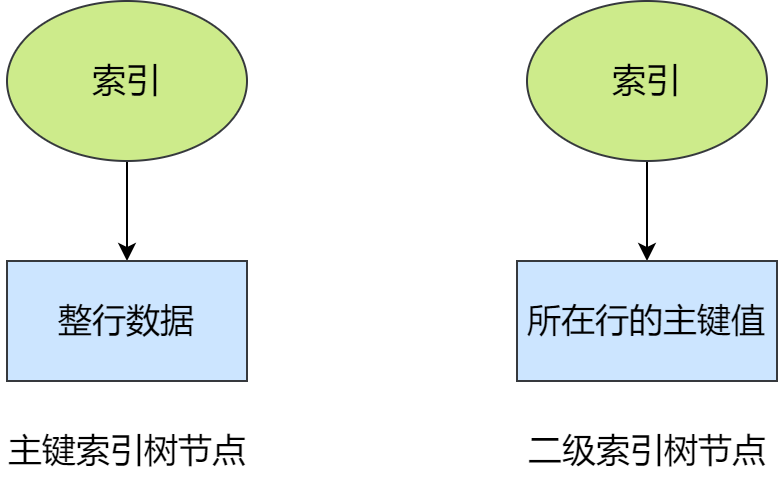
聚集索引和非聚集索引
在 MyISAM 引擎中,由于索引和数据存储在不同的两个文件中,所以其主键索引树和二级索引树是一样的,即二级索引树叶子节点中的数据是整行数据,而非主键值。称这种索引为 非聚集索引。而 InnoDB 引擎中的索引则称为 聚集索引。
MyISAM
MyISAM 引擎使用 B+ 树作为索引结构,叶节点的 Data 域存放的是数据记录的地址。下图是 MyISAM 主键索引的原理图:
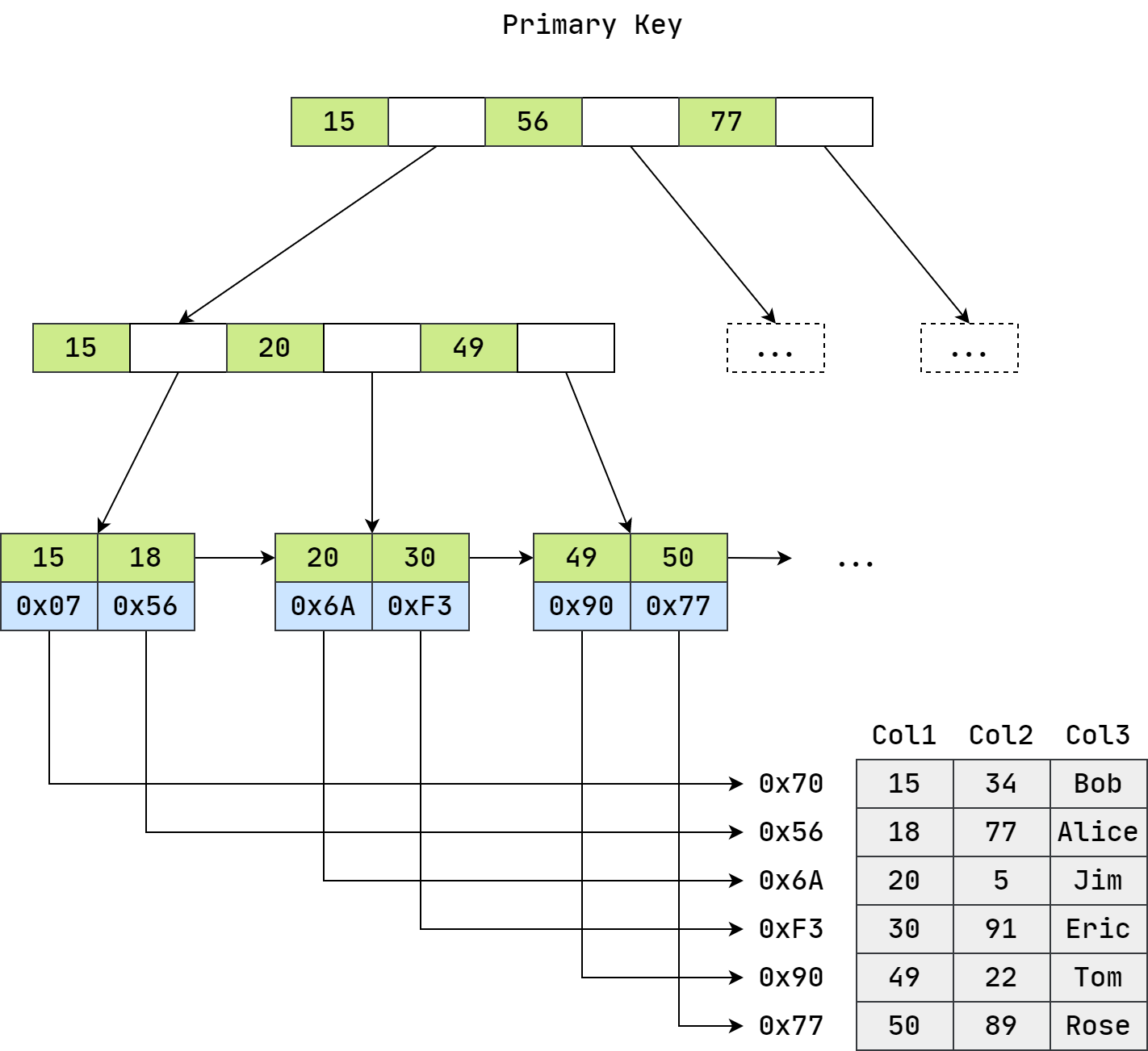
在 MyISAM
中,主键索引和辅助索引(Secondary key)在结构上没有任何区别,只是主键索引要求
Key 是唯一的,而辅助索引的 Key
可以重复,如果给其它字段创建辅助索引,其结构图如下:
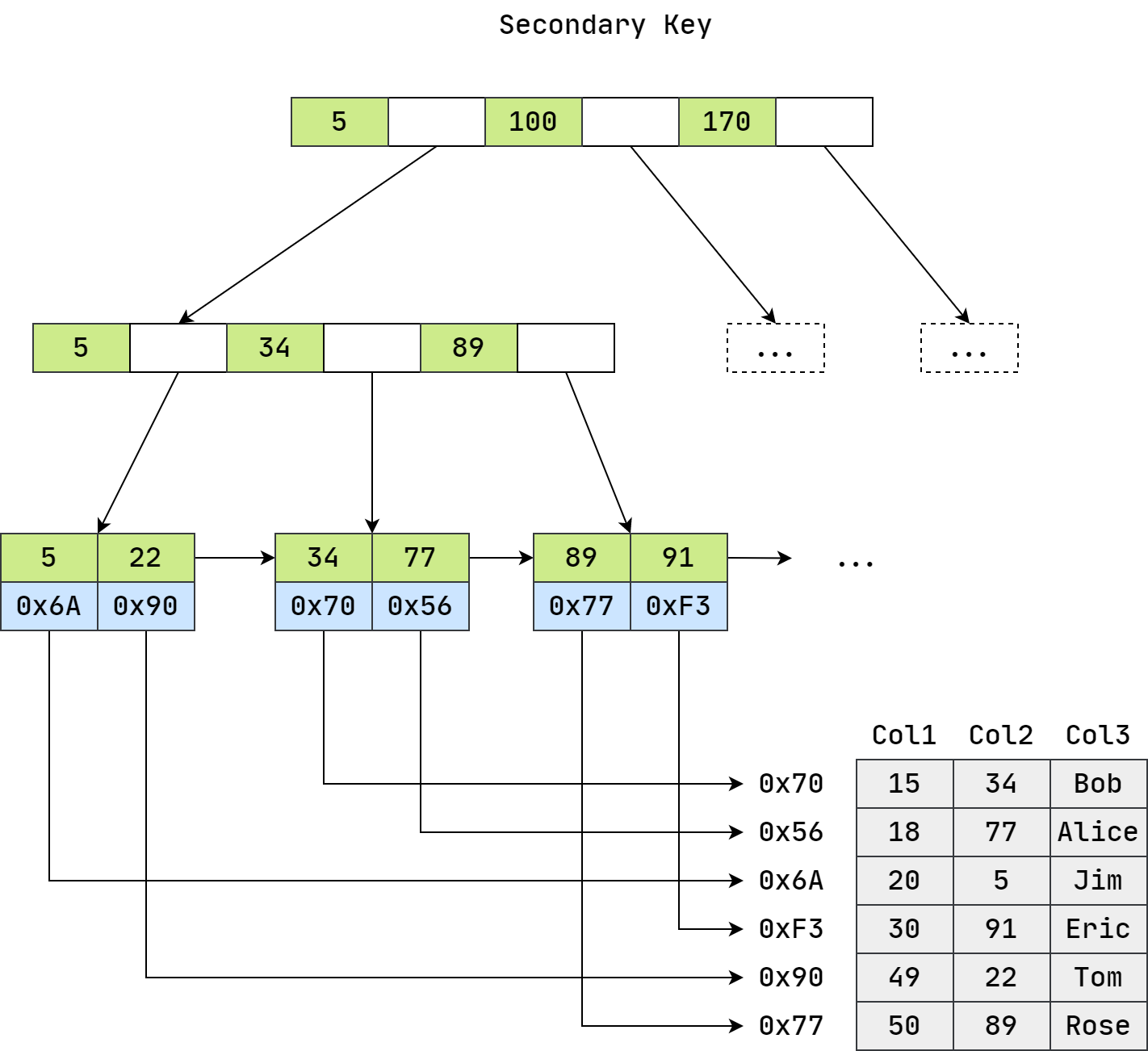
根据上面两张图,首先按照 B+ Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 Data 域的值,然后以 Data 域的值为地址,读取相应数据记录。
可以看到,MyISAM 存储引擎,索引结构叶子节点存储关键字和数据地址,也就是说索引关键字和数据没有在一起存放,体现在磁盘上,就是索引在一个文件存储,数据在另一个文件存储,例如一个 user 表,会在磁盘上存储为三个文件:
- user.frm(表结构文件)
- user.MYD(表的数据文件)
- user.MYI(表的索引文件)
MyISAM 的索引方式也叫做非聚集索引。
InnoDB
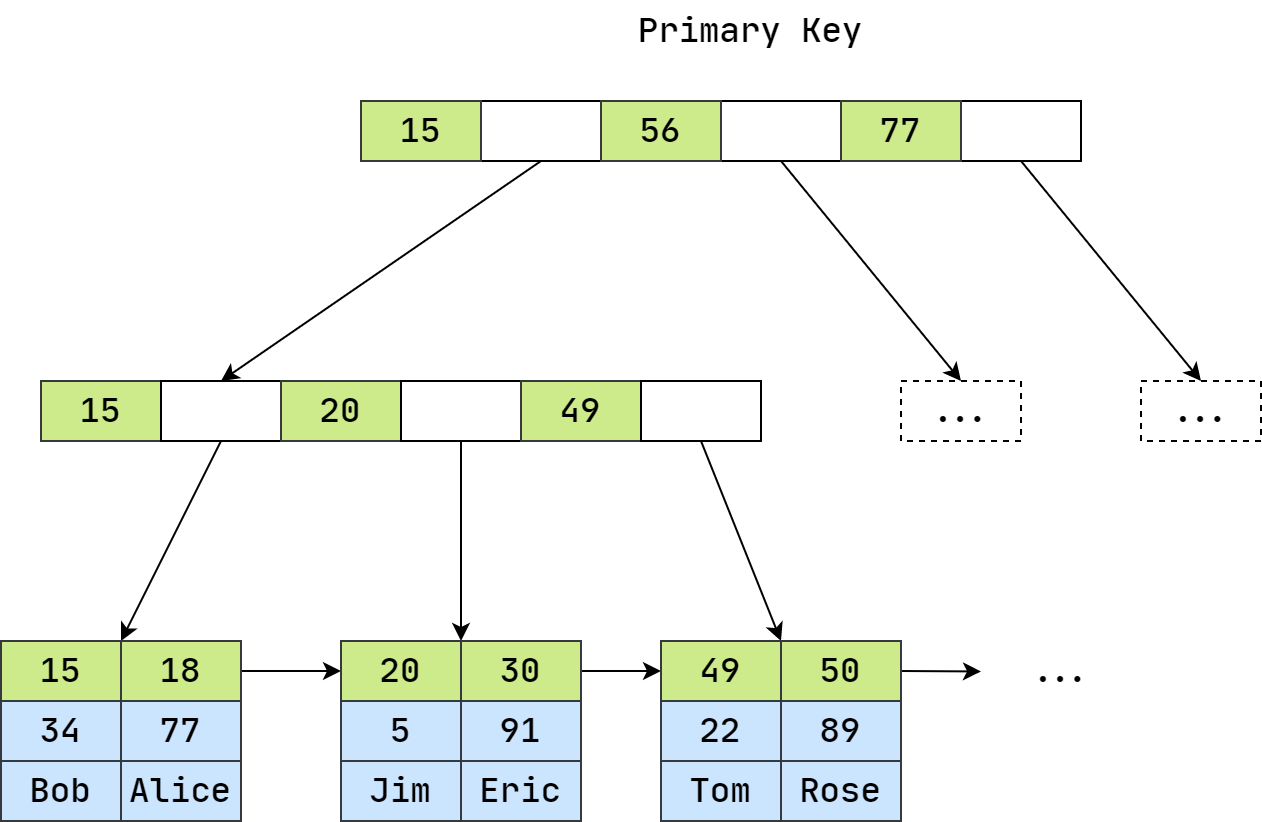
在 InnoDB 存储引擎的主键索引树的叶子节点中,索引关键字和数据是在一起存放的,其结构如图所示:
对于 InnoDB 的辅助索引树而言,其叶子节点上存放的是索引关键字和对应的主键,其结构如图所示:
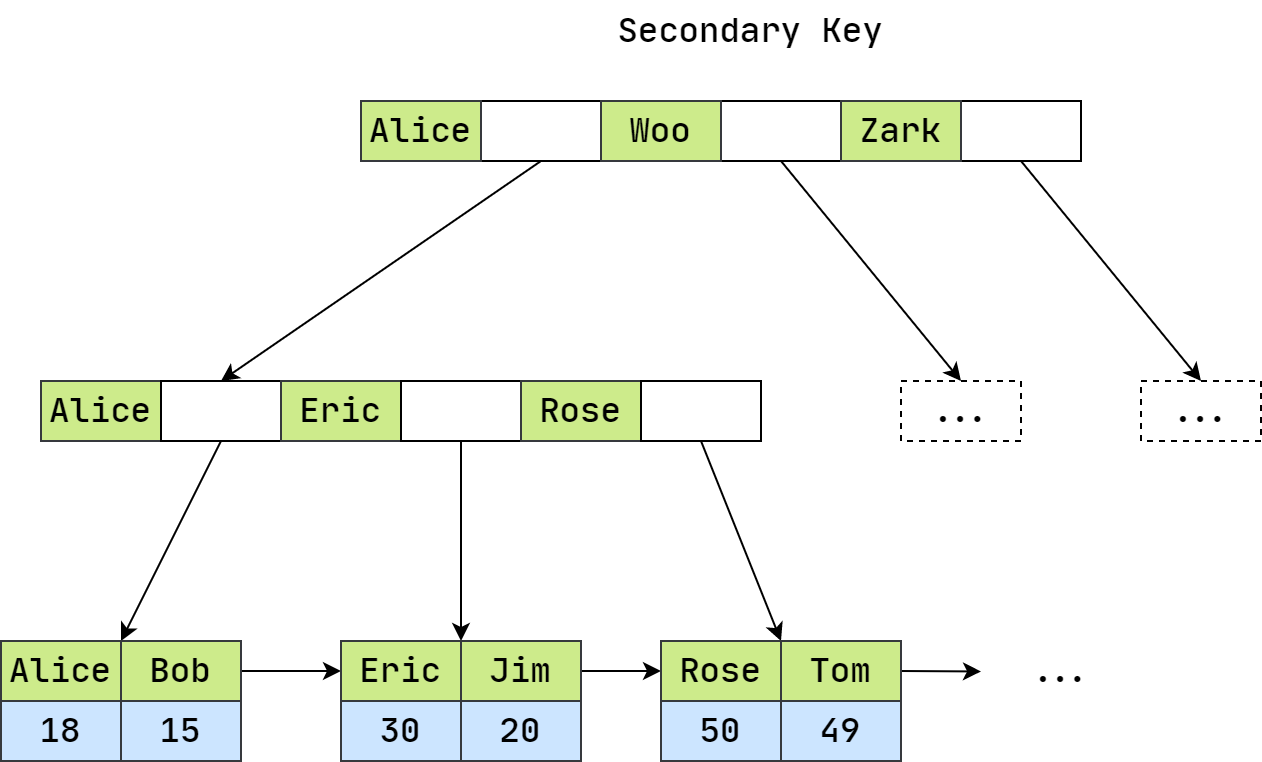
在辅助索引的 B+ 树中,会先根据关键字找到对应的主键,然后再去主键索引树上找到对应的行记录数据。从索引树上可以看到,InnoDB 的索引关键字和数据都是在一起存放的,体现在磁盘存储上,例如创建一个 user 表,在磁盘上只存储两种文件:
- user.frm(存储表的结构)
- user.ibd(存储索引和数据)
InnoDB 的索引树叶节点包含了完整的数据记录,这种索引叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集,所以 InnoDB 要求表必须有主键(区别于MyISAM可以没有),如果没有显式指定,则 MySQL 系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则 MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,这个字段长度为 6 个字节,类型为长整形。
自适应哈希索引
对于 InnoDB 存储引擎来说,如果它检测到同一个二级索引树不断被使用,那么该引擎会在内存上根据二级索引树上的二级索引值,在内存上构建一个哈希表,以此来减少回表的次数以加速搜索。
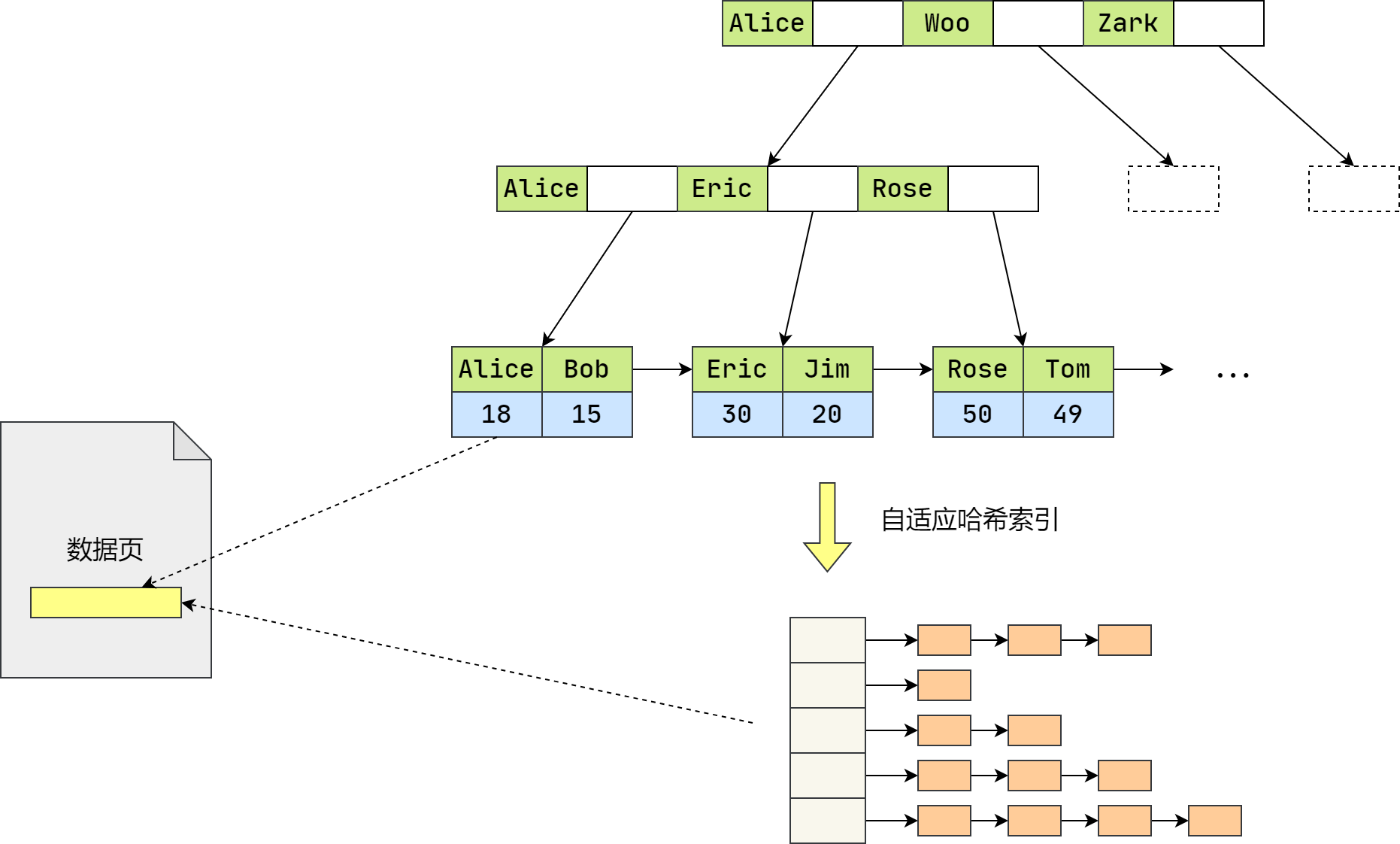
注意:自适应哈希索引本身的数据维护也是需要耗费性能的,并不是说自适应哈希索引在任何情况下都会提升二级索引的查询性能。
官方文档的解释如下:
In MySQL 5.7, the adaptive hash index search system is partitioned. Each index is bound to a specific partition, and each partition is protected by a separate latch. Partitioning is controlled by the innodb_adaptive_hash_index_parts configuration option. |
简单来说,就是在 MySQL 5.7
版本后,自适应哈希索引搜索系统会被分区,在默认情况下,自适应哈希索引搜索系统是开启的,由
innodb_adaptive_hash_index 变量来进行控制。在默认情况下会有
8 个分区,由 innodb_adaptive_hash_index_part
变量来进行控制,最大值为 512。
在每个分区中都会有一个单独的锁来控制并发操作,而在 5.7 版本之前,只使用了一个锁来保护整个哈希索引搜索系统,这会成为系统的瓶颈所在。
此外,哈希索引可能只构建了部分内存,仅仅包括那些经常访问到的页面。如果哈希索引搜索系统成为了系统的瓶颈,那么就可以考虑将其关闭而提高性能。